ai agent orchestration
AI Agent Orchestration in Practice: One Operator, 52 PRs, 11 Repos in a Day
A field report on AI agent orchestration in practice: how one operator directed AI coding agents across 52 pull requests and 10+ repositories in a single day — the operating model, the honest evidence, and how to evaluate it.

AI Agent Orchestration in Practice: One Operator, 52 PRs, 11 Repos in a Day

TL;DR — AI agent orchestration is the practice of one human operator directing multiple autonomous AI coding agents in parallel — owning scope, sequencing, verification, and merge risk while the agents do the implementation. This is a field report from a single ordinary day: 52 pull requests and 123 commit-events across 10+ production repositories, spanning product, authentication, billing, CI/CD, and SEO. The interesting part isn't the volume. It's that the bottleneck moved from writing code to judgment — deciding what to build, in what order, and what is safe to merge.
Key takeaways
- One operator, one ordinary day: 52 pull requests · 123 commits · 11 production repositories, spanning product, auth, billing, CI/CD, and SEO.
- The skill that scales is not typing code — it is orchestration quality: choosing targets, sequencing, verifying, and owning merge risk.
- It works when work is split by repo and responsibility, PRs stay small, and every PR carries verification evidence — and it breaks without those guardrails.
- Throughput is a signal, not a trophy. The honest metric is PR acceptance and defect rate, not raw commit count.
- Hiring for this? Ask for a real multi-repo agent system and throughput-with-quality metrics — not a single chat demo.
The common take on AI and software is "it makes coding faster." That's the small version of the story. A faster autocomplete still leaves one engineer working one problem at a time.
The bigger shift is this: a single operator can now keep many independent engineering lanes moving at once without losing the thread on correctness, deployment risk, or repository ownership. That isn't a typing-speed improvement. It's a change in what one technical person can be responsible for in a day.
This post is the operator's view from inside that loop — what the day actually looked like, the operating model that makes it hold together, the honest limits of the evidence, and how to evaluate anyone who claims they can do the same. For a higher-throughput companion day — 99 PRs and 230 commits in 24 hours — and the seven mechanisms underneath it, see Agentic Engineering: How One Operator Shipped 99 PRs in 24 Hours.
What AI agent orchestration actually is
AI agent orchestration is the coordination layer that lets one operator run multiple AI coding agents at the same time: scoping each agent a task, reviewing its diff, sequencing cross-repo dependencies, and deciding what merges. Frameworks like LangGraph, CrewAI, and AutoGen orchestrate agents inside a single program. The operating model here is the same idea applied one level up — a human orchestrating agents across a real, multi-repo codebase.
The control layer is not a bigger model. It is human judgment plus enforced conventions plus verification. The agents implement; the operator chooses targets, preserves boundaries between repositories, inspects the output, and owns the decision to ship. When people picture "AI writing code," they picture the implementation step. In practice that step is the cheap part. The expensive parts — scope, sequencing, review, and risk — are exactly the parts that stay human.
A representative day: 52 PRs across 11 repositories
On June 2, 2026, I used an AI-native workflow to direct, review, sequence, and land 52 pull requests and 123 commit-events across more than ten production repositories in a single day. It was a normal working day, not a stunt run.
| Metric | Value |
|---|---|
| Date window | June 2, 2026 (one calendar day, ET) |
| Pull requests | 52 |
| Commit-events | 123 |
| Repositories touched | 11 (all production, none archived) |
| Work types in one day | product, runtime fixes, auth/security, CI/CD, billing, SEO, docs |
| Evidence standard | every PR body carried verification notes |
A caveat up front, because it matters for trust: commit count is a throughput signal, not a quality trophy. Merge commits inflate it, and many commits were docs, CI, or internal tooling with no public surface. PR-level review is a far better quality signal than the raw number. The distinctive thing about this day is not the count — it is the breadth and the risk surface: a single operator moving across seven categories of work, several of them high-stakes, in one coordinated review-and-merge process.
Here is how that day broke down by lane:
| Lane | Examples from the day | Why it matters |
|---|---|---|
| Product & UX | self-serve billing button, public-site navigation, login alignment | User-visible product movement |
| Runtime bug fixes | hydration-mismatch fixes, a render-loop fix, a broken asset route | Production stability and live UX |
| Auth & security-adjacent | passkey hardening, OAuth callback repair, magic-link recovery | High-risk surfaces where correctness is non-negotiable |
| CI/CD & infrastructure | workflow composites, version pinning, runner storage fixes | Cross-repo delivery reliability |
| Billing readiness | dormant live-payment flow, webhook hardening, sandbox docs | Business-critical work without prematurely enabling risk |
| SEO & analytics | analytics wiring, FAQ schema, byline/E-E-A-T work | Growth and discoverability |
| Docs & agent-operability | architecture maps, plan hygiene, context hooks | Less future coordination drift |
No single one of those is remarkable. Doing all of them in one day, each scoped to its own PR with verification notes, is the point.
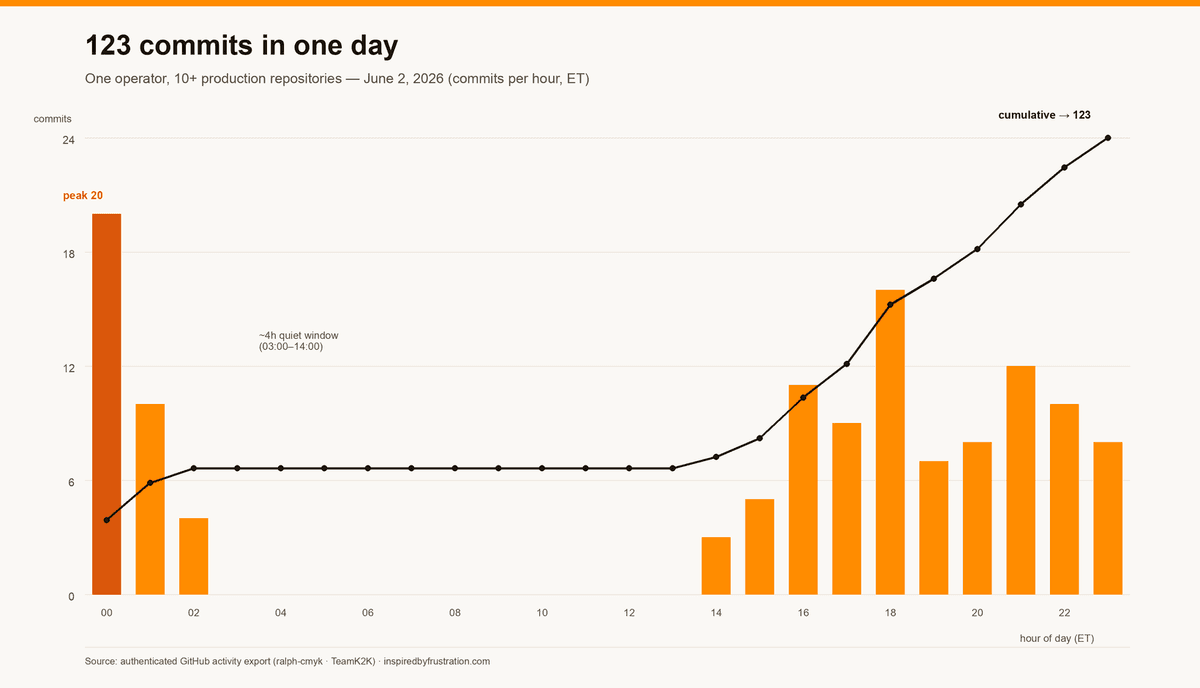
123 commits across one day, by hour (ET): an early-morning burst, a ~4-hour quiet window, then the evening push — cumulative total reaching 123. Source: authenticated GitHub activity export (ralph-cmyk · TeamK2K).
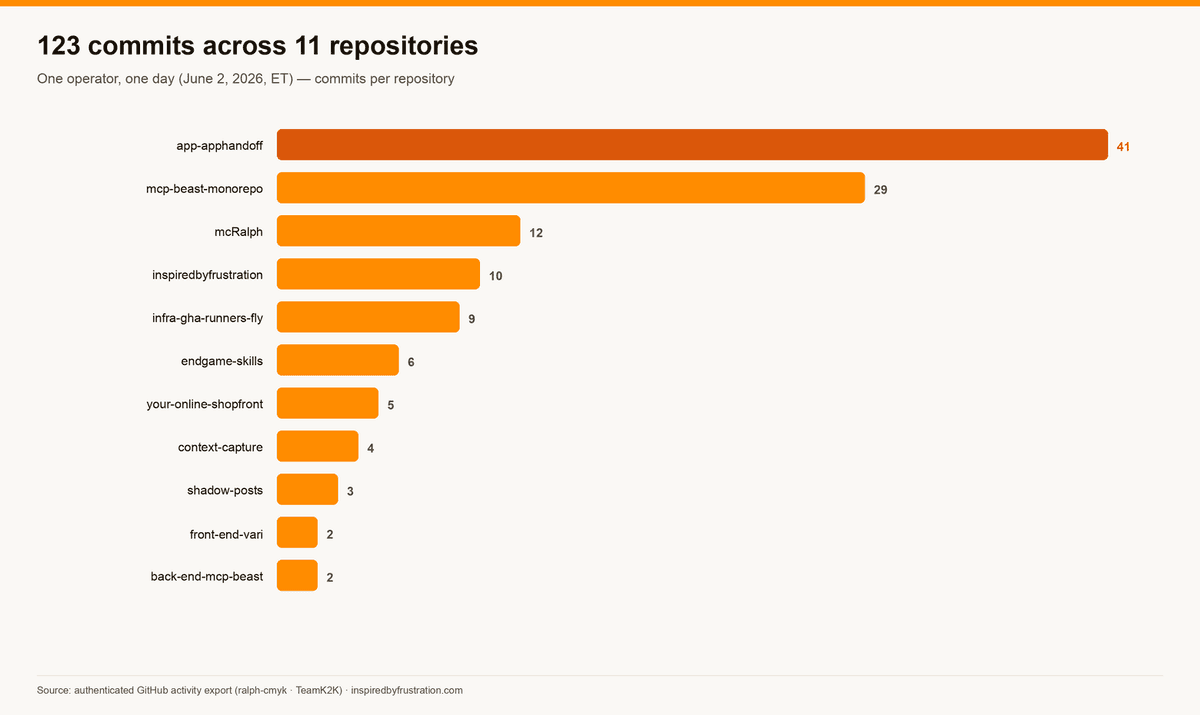
The same 123 commits split by repository — 11 production repos in one day. Breadth across products and concerns, not depth in one, is what the operating model buys.
From pair programmer to operator
A senior engineer using AI as a pair programmer makes one loop faster: understand the issue, write the code, test it, open the PR. A senior engineer operating agents runs many of those loops at once and spends their own attention on the layer above the code.
| Dimension | AI-accelerated developer | AI-native operator |
|---|---|---|
| Scope | One repo or product lane | 10+ repos in parallel |
| Daily PRs | Often 1–4 meaningful PRs | 52 |
| Primary AI use | Pair programmer | Multi-agent execution and review pipeline |
| Human role | Implementer + reviewer | Operator, reviewer, sequencer, risk owner |
| Main risk | Code correctness | Runtime, deploy, auth, billing, CI, and SEO risk |
| Coordination | One branch or sprint area | Cross-repo dependency sequencing |
This is the real promotion AI gives a strong engineer: it moves you up a level, from typing code to managing a portfolio of work. It is closely related to, but distinct from, day-to-day AI pair programming — the difference is how many lanes you can hold at once without dropping correctness. The skill that scales is not prompting. It is orchestration quality.
What makes it scale — and what breaks it
Orchestration scales when the surrounding system makes parallel work safe to review and cheap to roll back. It collapses when any one agent's change can quietly break another lane.
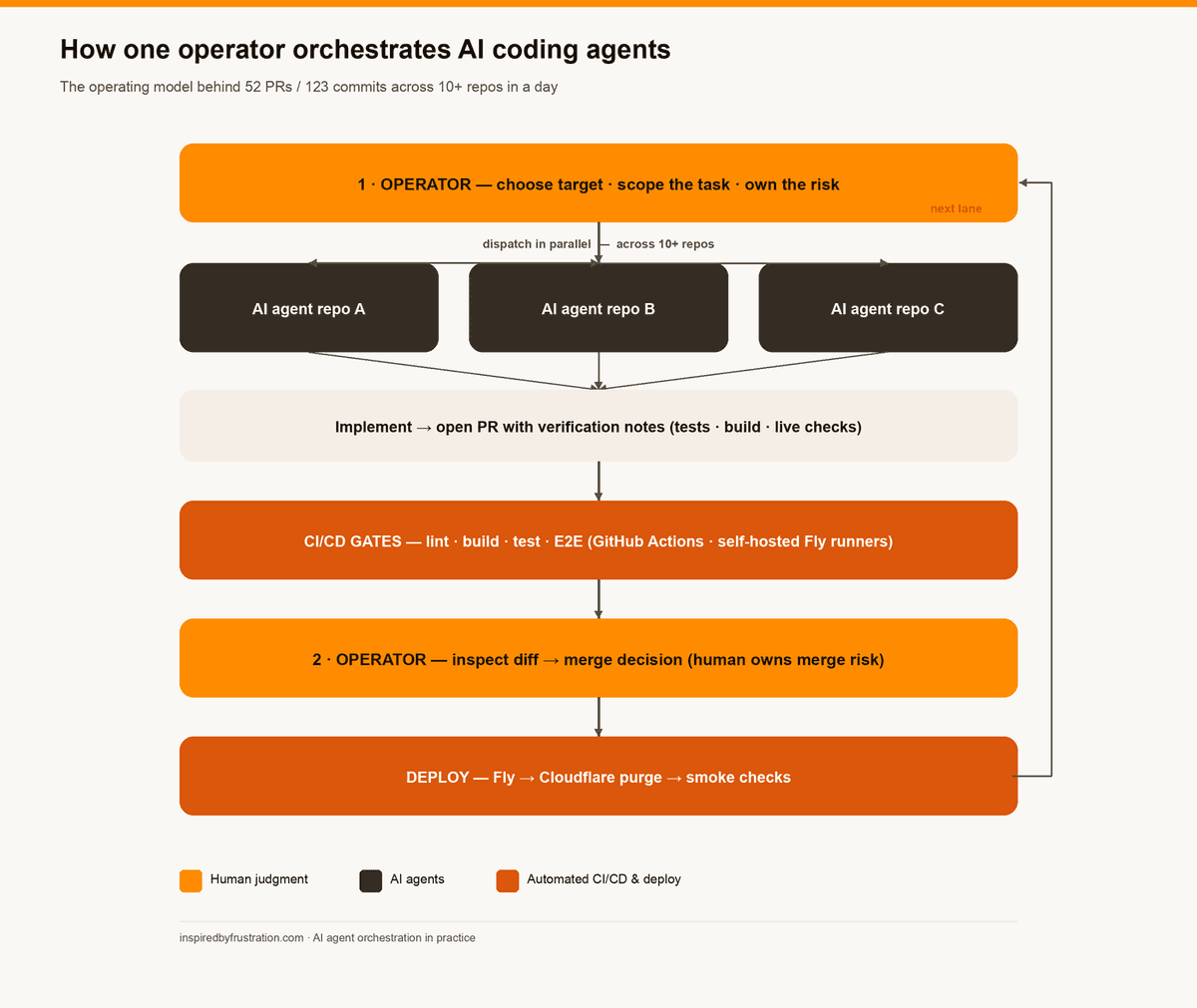
How the flow works end to end: the operator dispatches parallel agents across repos; every change clears the same CI/CD gates (GitHub Actions on self-hosted Fly runners) before a human owns the merge — then Fly deploy, Cloudflare purge, and smoke checks.
The mechanisms that did the heavy lifting:
- Small PRs. Narrow diffs keep both review and rollback surfaces small.
- Work split by repository and responsibility boundary, not bundled into one giant change.
- Verification notes inside every PR body — not just a summary of what changed, but evidence it works.
- Shared CI composites across repos, so workflow logic doesn't drift one-off per project.
- The human owns merge risk. Agents implement; the operator decides what is safe to land.
What breaks it is the inverse: oversized PRs, fuzzy repo boundaries, no verification discipline, and an operator who trusts output they didn't inspect. The deeper, mechanism-level version of this — and how to build the stack from scratch — is in the 99-PRs-in-24-hours field report, and the tooling layer that makes agents useful across repos is covered in MCP Server Architecture.
What the work looked like, in code
None of this is magic, and none of it is "the AI did it alone." Three patterns carried the day. They're shown here illustratively — the real diffs lived in private repos, but the shape is the point.
1. The unit of work is a small PR that carries its own proof. Every change ships with verification evidence in the PR body — not just a summary — so review and rollback stay cheap and an agent's output is never trusted blind:
fix(marketing): make footer sync to stop client-graph render loop
Root cause: an async Server Component (the footer) was reachable from the
client component graph, which forced the whole route dynamic and blocked
soft navigation to /projects.
Fix: move footer data to a synchronous boundary; delete the runtime fetch.
Verification:
bun run build ✓
bun run test ✓ (+3 cases)
curl -sIL <url> | grep -i strict-transport ✓
live: /projects soft-nav restored · /api/projects calls during nav: 0
2. The operator runs a loop, not a keyboard. Each lane is one repo or one responsibility boundary, with many in flight at once; the human keeps the parts that don't delegate well:
# one lane per repo / responsibility boundary — several active at once
scope=$(choose_next_target) # human: pick and scope the work
dispatch_agent "$scope" # agent: implement in an isolated worktree
inspect_diff # human: read every change, not just the summary
run_pr_gates # lint · typecheck · build · test · e2e
merge_if_safe # human: owns the merge decision
# repeat across 11 repos without losing the thread on correctness
3. Shared CI is what keeps parallel repos from drifting. Instead of copy-pasting workflow YAML into every repo, each one calls the same versioned composite — one source of truth, gated the same way everywhere:
# every repo's CI references the same pinned composite, not its own copy
- uses: TeamK2K/infra-gha-runners-fly/.github/actions/setup-runner@v2
- uses: TeamK2K/infra-gha-runners-fly/.github/actions/workflow-doctor@v2
The pattern is consistent: agents produce diffs quickly, and the operator's leverage is the system around the diffs — scoping, proof, and shared gates. For the deeper mechanics, see Agentic Engineering: 99 PRs in 24 Hours.
The honest part: what this proof shows — and what it doesn't
I can prove that the work happened and that it carried verification. I cannot prove, from commit metadata alone, that every change became a live, deployed feature — and I won't claim it. Honest evidence is layered:
| Evidence tier | Result | What it means |
|---|---|---|
| PRs with documented verification | 52 / 52 | Every PR body included tests, build, lint, or live-check evidence |
| PRs with live/deployed/URL evidence | ~30 / 52 | The PR body referenced a live URL, curl, or deployment |
| Fresh live public-page spot checks | 9 / 9 passed | A read-only re-verification of sampled public surfaces, run after the fact |
The repositories are private, so a public reader can't click through and independently verify them. That changes the evidence standard, not the truth of it: the methodology, timestamps, PR numbers, and a fresh public-page sample are all preserved and auditable by anyone with authorized access. A commit is not a feature, a merge commit is not a fresh implementation, and "shipped" is a claim that has to be checked, not assumed. Saying so plainly is part of the work.
When orchestration is worth it — and when it isn't
This operating model is a multiplier in some situations and a liability in others.
It's worth it when:
- There are many independent lanes of work that can move in parallel (multi-repo products, backlogs of scoped fixes, maintenance plus features at once).
- A strong operator can own scope, review, and merge risk.
- Verification is cheap and automated — good tests, CI, and live checks.
It's the wrong tool when:
- The work is one deep, novel problem that needs sustained single-threaded thinking.
- Test coverage is thin, so fast output can't be safely verified.
- No one is accountable for what merges. Speed without an owner is just risk with a faster clock.
How to evaluate someone who says they can do this
If you're a founder or engineering leader hiring for AI-native development, the claims are easy to make and hard to verify. Ask for evidence, not vibes.
- Ask to see a real multi-repo system. "Show me work where multiple agents made changes across several repositories in a coordinated way." Anyone can demo a single chat session.
- Ask for throughput metrics that include quality, not just volume: PR acceptance rate, bugs introduced, test pass rate, cycle time, and how often a human had to override the agent.
- Ask how they prevent agents from breaking builds or shipping unsafe code — guardrails, review gates, and what stays human-led.
- Ask about rollback and audit — version control for prompts and agent definitions, plus a clear story for reverting a bad change fast.
- Ask what they would not automate. A credible operator has a sharp answer.
Those questions separate people who have run this in production from people who have read about it. If you want the work done rather than evaluated, that's what I do — see AI agent development and AI consulting.
Work with me
I help founders and teams build and operate AI-native engineering: orchestrating AI coding agents across real codebases, with the verification and review discipline that keeps fast shipping safe. If you need senior judgment on top of agent throughput — as an embedded operator or a fractional CTO — that's the work.
- Build with agents: AI agent development
- Strategy and review: AI consulting
- Embedded leadership: Fractional CTO
- Talk it through: Get in touch
FAQ
Can one developer really manage multiple AI agents at once? Yes — with the right operating model. The limit isn't how many agents you can launch; it's how much scope, review, and merge risk one person can own at once without dropping correctness. Small PRs, clear repo boundaries, and verification-in-PR are what make it sustainable rather than chaotic.
Is this just AI writing the code? No. The agents do the implementation, which is the cheap part. The operator owns the expensive parts: choosing what to build, sequencing cross-repo dependencies, inspecting every diff, and deciding what is safe to merge. The bottleneck moves from typing to judgment.
What's the difference between AI agent orchestration and using an AI coding assistant? An AI coding assistant makes one engineering loop faster. AI agent orchestration runs many loops in parallel and shifts the human into an operator role — reviewer, sequencer, and risk owner — across multiple repositories at once.
Do you need frameworks like LangGraph or CrewAI to do this? Not for orchestrating engineering work across a codebase. Those frameworks coordinate agents inside one application. Orchestrating real software delivery is mostly about conventions, scoped tasks, verification discipline, and tooling like MCP servers that give agents reliable access to your repos and systems.
How do you keep quality up when shipping that fast? Quality comes from narrow PRs, verification notes in every PR body, shared CI, and a human who owns the merge decision. Throughput without those guardrails isn't speed — it's deferred risk. The right metric is PR acceptance and defect rate, not commit count.
How is this different from "vibe coding"? Vibe coding leans on the model and accepts what comes out. Orchestration is the opposite posture: the operator stays accountable for scope, correctness, and what ships. The agents move fast; the human keeps the standards.
What stack does this require? Nothing exotic: agentic coding tools (Claude Code, Cursor), MCP servers for reliable repo and service access, isolated git worktrees so lanes don't collide, and shared CI composites so every repo is gated identically. The leverage is in the operating discipline, not any single tool.
Is this solo-only, or can a team adopt it? A team can adopt it, and the gains compound. The same discipline — small PRs, verification-in-PR, shared CI, clear repo boundaries — lets each engineer run several agent lanes instead of one. The bottleneck becomes review and judgment capacity, which is exactly where senior engineers add the most value.
related paths