agentic engineering
Agentic Engineering: How One Operator Shipped 99 PRs in 24 Hours
A field report on agentic engineering: 99 PRs, 230 commits, 80,000 LoC across 12 production repos in 24 hours — and the seven orchestration patterns that make it possible.
Agentic Engineering: How One Operator Shipped 99 PRs in 24 Hours
TL;DR — Agentic engineering at scale is a coordination problem, not a model problem. This is a field report on what that looks like in practice: 99 pull requests, 230 commits, ~80,000 lines of code across 12 production repos in 24 hours. What follows isn't about the output number — it's about the seven mechanisms that make that output possible, what fails without them, and how to build the same stack from scratch in a week.
There is a Reddit thread near the top of the agentic engineering SERP titled "18 months & 990k LOC later, here's my Agentic Engineering setup." That's a fair, honest field report from someone who built carefully over a year and a half. This post is the same shape but compressed: 24 hours, ~80k LoC, 12 production repos, one operator. The gap between those two numbers isn't raw coding speed — it's orchestration. Agentic engineering scales when the orchestration layer is built. It collapses when it isn't.
If you're an engineering leader sizing up where agentic coding is going, a Cursor or Claude Code power user trying to push past one-PR-at-a-time, or a founder wondering whether you can run an "engineering team of one" at scale, this is the operator's view from inside that loop.
The numbers (so we agree on what we're explaining)
A single 24-hour window on one operator's GitHub activity, all on private repos:
| Metric | Value |
|---|---|
| Pull requests opened | 99 (97 merged · 1 still open · 1 closed-unmerged) |
| Commits on default branches | 230 |
| Lines added | +80,350 |
| Lines removed | −15,255 |
| Repositories touched | 12 (all production, none archived) |
| Active hours of shipping | ~17 of 24 (4-hour quiet window for sleep) |
| Sustained cadence | One PR every ~13 minutes during active hours |
| Peak hour | 19 PRs in 60 minutes |
| Code-quality grade (random 25-PR sample) | A− average · GPA 3.61 · 5 A+ · 10 A · 4 A− · 3 B · 2 C · 1 D |
For context: the median commits-per-day per active developer in industry surveys hovers around 1.4–3. DORA's "elite" team performers ship 5–10 PRs per day across the whole team. An agentic setup running at this cadence puts a single operator in roughly the same throughput range as a small engineering team — which is a useful way to calibrate what you're actually building toward.
Methodology — how was the GPA computed? Random sample of 25 PRs from the 24-hour window, scored on five axes: correctness, test coverage, scope discipline, naming/idioms, and "would a senior reviewer approve as-is." Five A+ (4.3), 10 A (4.0), 4 A− (3.7), 3 B (3.0), 2 C (2.0), 1 D (1.0). Weighted GPA 3.61 = A− tier. The audit was scored by a model not in the writing loop, so it isn't marking its own homework.
Why this is hard (the failure mode you'll actually see)
If you've used Cursor or Claude Code seriously, you already know the naive setup:
- Open the IDE, attach a model, write a prose prompt.
- Watch the agent write code.
- Look at the diff, push, hope CI passes.
- Repeat.
That works for one task at a time. It does not work for 99 tasks in a day across 12 repos. The failure modes you hit, in the order you hit them:
- Drift mid-task. The agent invokes a sub-routine, returns its output, and silently drops the parent flow. Five PRs from now you realize three never actually landed.
- Invented shortcuts. "The diff looks small, I'll skip the test step." Three days later something subtle is broken in production and you spend a morning bisecting commits.
- Secrets in logs / env files committed. One bad
.envslip and you're rotating credentials and re-deploying. - Broken tests merged on green CI. Because CI ran the cached test set, not the new one.
- Unbounded review. You spend more time reviewing the agent's PRs than you would have spent writing the code yourself.
- No state across sessions. You close the IDE, come back tomorrow, and the agent has no idea what was mid-flight.
Most engineers hit one of these in week one and either dial down their ambition (back to one PR at a time, supervised) or push through and accept the chaos. The third option — the one that produces real fleet-scale output without dropping quality — is to build the orchestration layer.

7 mechanisms that make agentic engineering actually work
These are described as patterns. The implementations are mine; the patterns are reusable.
The orchestration stack at a glance
Before diving into each mechanism, here is how they layer. Each level depends on the one below it — you cannot skip Layer 2 and expect Layer 4 to hold.
flowchart TB
subgraph L7["Layer 7 — Cross-repo Coordination"]
T["Structured tickets via MCP\n(durable, survives IDE restarts)"]
end
subgraph L6["Layer 6 — Infrastructure"]
R["Self-hosted CI runners\n(10× faster · 10× cheaper)"]
end
subgraph L5["Layer 5 — Context Survival"]
H["IDE hooks — state injected on every turn\n(eliminates mid-flow drift)"]
end
subgraph L4["Layer 4 — Quality Gate"]
P["6-lens parallel pre-ship review\n(auto-fix + structured human decisions)"]
end
subgraph L3["Layer 3 — Hard Gates"]
G["Human gates + pre-ship-verify.sh\n(agent cannot rationalize past these)"]
end
subgraph L2["Layer 2 — State Tracking"]
M["Phase markers + JSON state file\n(auditable, session-survivable)"]
end
subgraph L1["Layer 1 — Deterministic Behaviour"]
S["Skills: versioned Markdown programs\n(not prompts — programs)"]
end
L1 --> L2 --> L3 --> L4 --> L5 --> L6 --> L7
classDef layer fill:#f8fafc,stroke:#cbd5e1,color:#1e293b
class L1,L2,L3,L4,L5,L6,L7 layer
1. Skills as the agent's operating system (Claude Code skills, Cursor rules)
A "skill" is a versioned Markdown file with YAML frontmatter that the agent reads first whenever a triggering phrase or slash command appears in chat. Claude Code skills, Cursor rules, and any equivalent prompt-as-program system all serve the same function: they convert volatile prompting into deterministic behaviour. A skill contains:
- The exact phase markers the agent must emit (one per major step)
- Hard rules ("never do X under any circumstance")
- A sub-skill return contract ("when you finish, emit this marker, then continue")
- Decision templates for human-in-the-loop gates
- A version number and a
last_updateddate the agent surfaces every time it loads
The reason this matters more than prompt engineering is that prompts are advice; skills are programs. An LLM with a strong skill loaded behaves the same way today as it did yesterday and as it will tomorrow. Without skills, you get a model whose behavior drifts every time the underlying weights are updated, every time the context window fills, every time you start a new chat.
A practical shape:
---
name: ship-flow
version: 4.13.0
last_updated: 2026-04-18
description: Ship local changes to GitHub via PR, with hard pre-ship gates.
---
## Hard rules
1. Never `git push --no-verify`.
2. Never auto-fix outside the computed ship scope.
3. The skill decides any fast paths. The agent never invents shortcuts.
## Phase markers (emit verbatim)
- `SHIP OPENING:`
- `PRE-SHIP READY:`
- `PHASE 2 PR:`
- `PHASE 2 MERGED:`
- `SHIP COMPLETE:`
## Flight checklist
1. Resolve default branch + fetch origin
2. Run pre-ship review (parallel sub-agents)
3. Apply auto-fixable findings; loop until clean
4. Run pre-ship-verify.sh (lint + typecheck + test + build)
5. Emit PRE-SHIP READY → human gate (A/B/C)
6. Push, open PR, watch CI, auto-merge on green
7. Post-merge cleanup
You don't need ten skills to start. You need three: ship, commit, and review. Everything else is leverage on top.
2. Phase markers as a write-ahead log in the transcript
Phase markers are the highest-leverage low-effort mechanism in the entire stack.
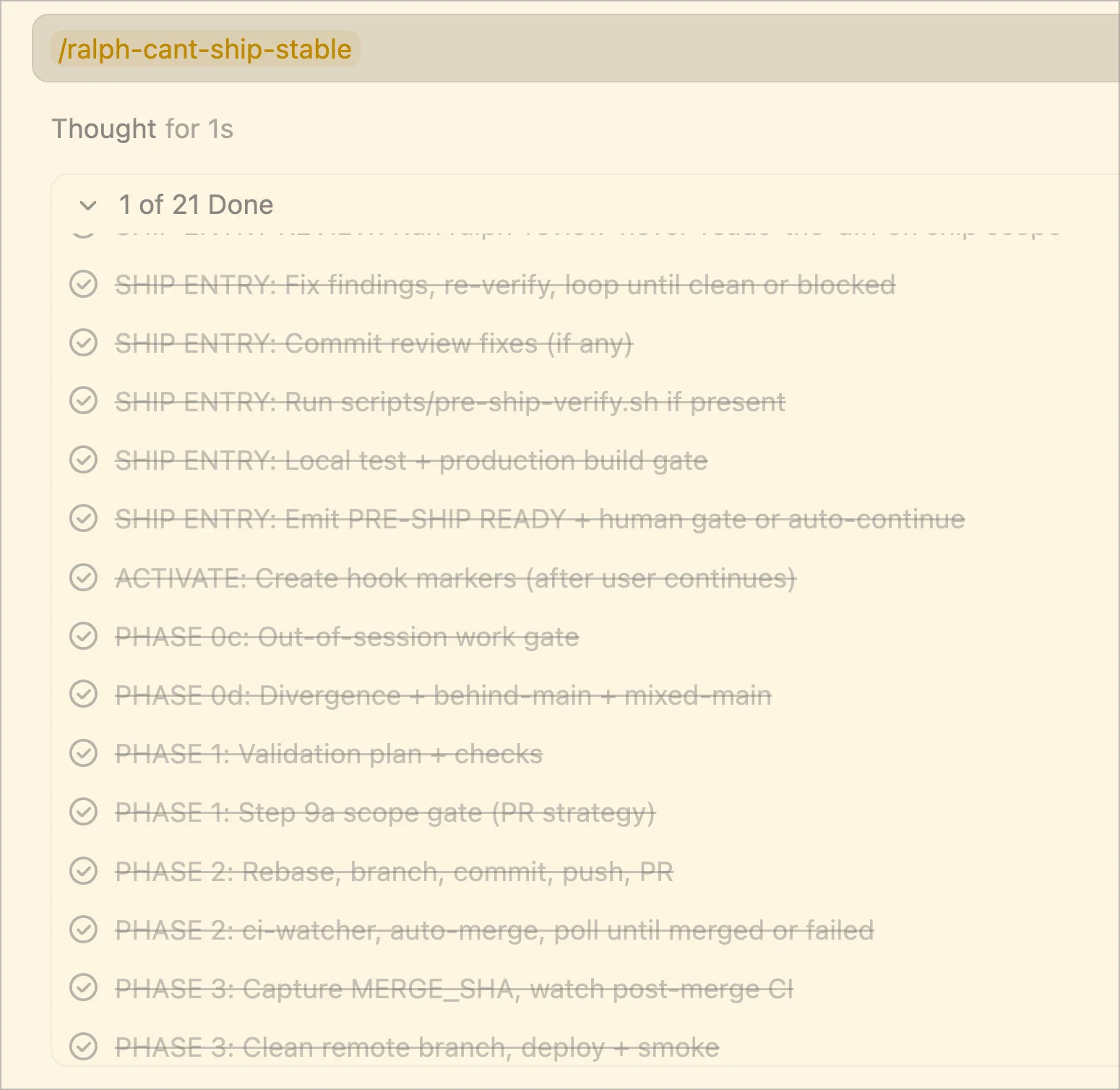 The phase markers as they actually appear in the IDE — each crossed-out line is a completed phase step, giving a real-time audit trail of exactly where the ship flow stands.
Every multi-step skill emits one-line markers as it progresses:
The phase markers as they actually appear in the IDE — each crossed-out line is a completed phase step, giving a real-time audit trail of exactly where the ship flow stands.
Every multi-step skill emits one-line markers as it progresses:
SHIP OPENING: v4.13 (1d ago) — continuing.
PHASE 0a COMPLETE: main · fetched at abc1234
SHIP ENTRY REVIEW: clean
PRE-SHIP READY: web-app · 3 files · verify: ok · test: ok · build: ok
MARKERS ACTIVE: a3f2c1d
PHASE 0c COMPLETE: scope clean
PHASE 1 COMPLETE: lint ✓ typecheck ✓ test ✓ build ✓
PHASE 2 PR: #1488 created
PHASE 2 CI WAIT: e2e: pending
PHASE 2 MERGED: #1488 · merge 7e9d4ab
PHASE 3 DEPLOY: ok, status healthy, smoke passed
PHASE 3 CLEANUP: branch deleted, worktrees pruned, main synced
SHIP COMPLETE: web-app > PR #1488 > merged > deployed
That transcript is auditable in three ways:
- A human scrolling can see exactly where every PR is in its journey — no more "wait, did the deploy actually happen?".
- The next agent turn can re-derive state by reading those markers (or, more reliably, a JSON state file the markers write into).
- A self-audit rule can run on every turn: "Read the state file. Emit a one-line
RESUMING: last=<marker> · next=<phase>status. Then act." Any drift surfaces immediately because the audit fails.
Pair the markers with a JSON state file at /tmp/<session>.json that the agent re-reads on every turn. Markers are for humans and audit. State file is for the agent itself.
3. Hard human gates the agent cannot rationalize past
The single most important rule in any production-grade agent skill is this:
No agent-invented shortcuts. The skill decides any fast paths. The agent never invents shortcuts because the diff "looks small", the review "was clean", or the user said "just ship it".
That's not optional. It's load-bearing. The moment an agent can rationalize past a gate ("this is just a typo fix, I'll skip the test"), you've lost. Quality erodes silently and you don't notice until production breaks.
In practice this means three things:
-
Pre-ship verification is mandatory. A
pre-ship-verify.shscript that runs lint, typecheck, test, and a production build, hard-gated. Runningnpm testdirectly does not satisfy it. Either the canonical script ran clean or you stop. -
A human approval gate before push. The skill emits a one-line
PRE-SHIP READY:marker with the diff scope, then a structured A/B/C decision: A) ship now, B) stop and resume later, C) cancel. No markers proceed until the human picks A. -
Skill-decided auto-continue is the only fast path. When the skill (not the agent) detects all-green verify + tight scope (≤8 files, ≤200 LoC) + no risky signals (migrations, sensitive files, mixed-default-branch), it can append
· auto-continued (light-mode)to the marker and skip the A/B/C gate. The user can still interrupt the next turn with "stop". This is what lets the 13-minute cadence work — most ships don't actually need the human gate.
The trick is the asymmetry: the agent never decides to skip the gate. The skill — which is just text the agent reads — does. That makes the skip rule auditable and tunable.
4. Pre-ship review by parallel reviewers on a fast model
This is where code quality lives or dies.
Before any push, the ship skill mandatorily runs a review sub-skill. That sub-skill dispatches six parallel sub-agents on a fast/cheap model, each with a different lens:
| Lens | Looks for |
|---|---|
| Correctness | Logic errors, edge cases, null handling, state bugs, intent vs implementation |
| Performance | N+1 queries, unnecessary allocations, algorithmic waste, render cost |
| Security | Auth gaps, input validation, secrets exposure, injection vectors |
| Testing | Untested paths, weak assertions, brittle tests, missing edge cases |
| Standards | Naming, patterns, project conventions, framework idioms |
| Docs impact | Stale READMEs, mismatched API docs, missing changelog entries |
Each sub-agent gets the diff and returns structured findings only — file path, line range, one-sentence issue, one-sentence fix, and a single boolean: is this auto-fixable (no product decision needed) or needs-user-decision (a real trade-off)?
The orchestrator then:
- Auto-fixes everything in the auto-fixable bucket without asking.
- Surfaces the needs-user-decision bucket as A/B/C choices.
- Re-runs the review on the fixed diff. Loops until clean or blocked.
For trivial changes (≤3 files, ≤30 LoC) only correctness + standards run. Six lenses on a typo fix is wasteful.
The grade distribution: 5 A+, 10 A, 4 A− (76% at A− or better), 3 B, 2 C, 1 D. GPA: 3.61. That distribution doesn't happen on prose-prompted code. It happens because every PR runs the same six-lens review before it lands.
Here is how the 25-PR sample broke down:
xychart-beta
title "25-PR Code Quality Audit — Grade Distribution"
x-axis ["A+", "A", "A-", "B", "C", "D"]
y-axis "PRs in sample" 0 --> 11
bar [5, 10, 4, 3, 2, 1]
The lower-graded PRs share a single failure mode — tests didn't keep pace with the change, or an escape hatch like as any slipped through. The high-graded ones all share the same opposite shape: tests added, scope tight, no smells.
The cost is low because the reviewers run on a fast model (Sonnet/Haiku tier, not Opus). One pass costs cents, not dollars.
5. IDE hooks that inject state on every turn (Claude Code workflow recovery)
Agents drift. The most common drift mode I see, after a year of this:
The agent invokes a sub-skill (say, the review skill from #4). The sub-skill returns its findings. The agent treats the sub-skill's return as a terminal response, summarizes it back to me, and stops — silently dropping the parent ship flow.
Two PRs later you notice nothing has actually been pushed. The fix isn't to write better prompts. It's to inject the current state into every single agent turn using an IDE-level hook.
In Claude Code, the hook is UserPromptSubmit. In Cursor it's sessionStart (per session, since Cursor doesn't yet expose per-turn additional_context). The hook is a ~30-line bash script:
#!/usr/bin/env bash
# Read the most recent ship-state JSON file
state=$(ls -t /tmp/ship-state-*.json 2>/dev/null | head -1)
[[ -z "$state" ]] && exit 0
phase=$(jq -r '.current_phase' "$state")
last_marker=$(jq -r '.last_marker' "$state")
next_step=$(jq -r '.next_step' "$state")
# Inject as a system reminder on the next turn
cat <<EOF
<system-reminder>
Active ship in progress.
Last marker: $last_marker
Current phase: $phase
Next required step: $next_step
Continue with the next pending phase. If you finished a sub-skill,
emit the corresponding transition marker now and proceed.
</system-reminder>
EOF
Pair this with a self-audit rule in the skill: every turn between the opening and closing marker must begin with a three-line audit (read state file → emit RESUMING: line → act on next phase). When the hook injection and the agent's internal model disagree, trust the injection.
This single mechanism eliminates more than half of the "the agent forgot" failures in practice. It's the difference between a 17-hour shipping run that completes cleanly and one that needs babysitting every 90 minutes.
6. Self-hosted GitHub Actions runners as a multiplier
This is the boring infrastructure piece, and it's the one most people skip until they hit a wall. At 99 PRs/day, self-hosted GitHub Actions runners pay for themselves on day one.
The math is unforgiving. At 99 PRs per day, each running a typical 3–5 GitHub Actions jobs, you're looking at:
| GitHub-hosted | Self-hosted (Fly Machines) | |
|---|---|---|
| Average job runtime | 3–8 min | 1.5–4 min (NVMe cache, pre-installed deps) |
| Queue time | 10–60 sec | 2–8 sec |
| Cost per Linux minute | $0.008 | ~$0.0003 (amortised over the pool) |
| Concurrent jobs cap | 20 (free) / 60 (team) | Whatever you provision |
| Daily cost at 99-PR pace | ~$150–250 | ~$15–25 |
| First-day payback | No | Yes |
The setup that pays back is two pools:
- A small always-on pool (one tiny VM) for cron-style work — status updates, sitemap regeneration, periodic checks.
- An on-demand medium pool (max ~6 machines, 8 vCPU / 16GB each) that wakes up for CI/build/test/E2E jobs and goes to sleep when idle.
The runner image bakes in everything common: language toolchains, Playwright system dependencies, deploy CLIs (flyctl, wrangler, supabase), database clients. Workflows skip the install step entirely. A "set up Node + install deps" sequence that takes 90 seconds on a GitHub-hosted runner takes 6 seconds on yours.
Two pieces of infrastructure pay back disproportionately:
Composite actions for the boring parts. Things like checkout-fast, setup-runner, bun-install, infisical-env — published once at org/runners-repo/.github/actions/<name>@main, consumed everywhere with a one-line uses: step. Workflows shrink from 80 lines to 25.
A runner-cache contract via env vars. The runner sets BUN_INSTALL_CACHE_DIR=/cache/bun, TURBO_CACHE_DIR=/cache/turbo, PLAYWRIGHT_BROWSERS_PATH=/cache/playwright, npm_config_cache=/cache/npm at job start. Workflows don't need actions/cache at all — the cache is a local NVMe directory, persistent across jobs. Combined with a node_modules cache via runner hooks (two-pass rsync --link-dest restore + a NM_CACHE_HIT env var to signal whether a fresh install is needed), the average install time on a warm runner is 3–8 seconds.
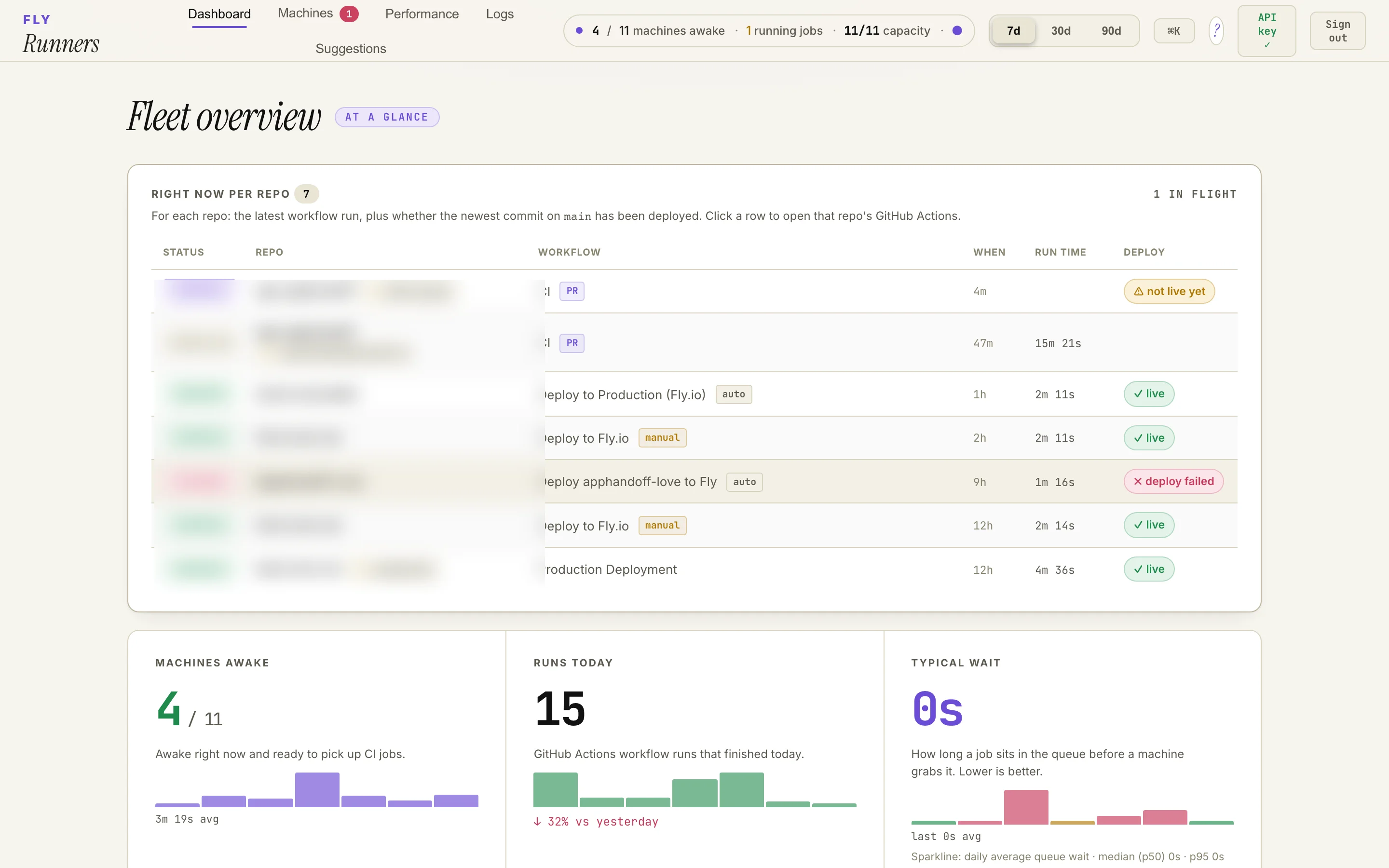
A live dashboard showing pool status, queue depth, and per-repo job latency is a one-day project that pays back the first time something breaks at 2am and you can see exactly why.
Live runner-pool dashboard at 1440×900 — fleet overview at a glance: machine count, in-flight jobs, capacity headroom, per-repo deploy state, and median queue wait. Repo names redacted; everything else is a real production snapshot.
For more depth on the CI side specifically, see How We Made Our CI/CD Pipeline 10x Faster.
7. Cross-repo coordination through structured tickets, not chat
The conductor's bottleneck at fleet scale is not typing speed. It's coordination across repositories.
Twelve repos in flight in a single day means twelve different mental models, twelve different test conventions, twelve different deploy targets. No human — and no agent — holds all that context. The naive approach is to chat with the agent across repos: "fix this in repo A, then check repo B, then update repo C." That breaks immediately. Chat is volatile state.
The pattern that works is structured tickets, exposed via an MCP server (or any API the agent can call from any repo):
- When an agent in repo A finds something that needs to change in repo B (an API consumer needs updating, a downstream test is breaking, a shared schema needs evolving), it doesn't try to edit repo B directly. It files a ticket against repo B with title, description, role tags, acceptance criteria, evidence (audit IDs, URLs, screenshots), and implementation notes.
- The ticket is long-lived state. The conductor (or another agent) picks it up later from a triaged inbox.
- When the work in repo B lands, the ticket's
merged_prfield gets updated and the original requester sees it.
The trick is that tickets survive sleep, IDE switches, and conversation resets. Chat doesn't. If you're running a multi-repo fleet, every cross-repo edit must go through a ticket queue, no exceptions. This is the mechanism that lets one operator hold the whole graph in their head at the level of granularity they actually need (open / in-progress / blocked / shipped) without having to remember the details of any single thread. Building this kind of cross-repo coordination layer is exactly what an MCP server is for.
A handoff ticket on this stack is auto-created during the dispatch phase of any skill run that produces an [HANDOFF] row in its plan. The agent never asks you to mentally hold the cross-repo todo. It writes it down, with structured fields, in a place that won't disappear.
The agentic engineering orchestration loop (what a typical day looks like)
Zooming in first — one ship, end to end — so the daily loop below makes sense:
flowchart LR
Start([SHIP OPENING]) --> Review[6-lens<br/>parallel review]
Review --> Fix{Fixable<br/>findings?}
Fix -->|yes| Loop[Auto-fix loop<br/>until clean]
Loop --> Verify
Fix -->|no| Verify[pre-ship-verify.sh<br/>lint · type · test · build]
Verify --> Gate{All green<br/>+ tight scope?}
Gate -->|yes| Auto[Skill-decided<br/>auto-continue]
Gate -->|no| Human[Human A/B/C gate]
Human -->|A| Auto
Auto --> Push[Push + PR]
Push --> CI[Self-hosted CI]
CI --> Merged([MERGED])
Merged --> Deploy[Deploy + smoke]
Deploy --> Done([SHIP COMPLETE])
classDef gate fill:#fef3c7,stroke:#a16207
classDef done fill:#dcfce7,stroke:#15803d
class Gate,Fix,Human gate
class Start,Merged,Done done
That sequence runs ~99 times in a 24-hour window, mostly on the auto path. Now zoomed out — what an actual agentic engineering day looks like as a coordination layer:
flowchart TB
subgraph Morning ["Morning planning (10 min)"]
A[Review overnight ticket inbox] --> B[Pick today's top 5 outcomes]
B --> C[Spawn agents in parallel branches/worktrees]
end
subgraph Loop ["Per-PR loop (every ~13 min)"]
D[Agent makes changes] --> E[6-lens parallel review]
E --> F{All green?}
F -- yes --> G[pre-ship-verify.sh]
F -- needs-user --> H[A/B/C gate]
G --> I{Light Mode + all green?}
I -- yes --> J[Auto-continue: push + PR]
I -- no --> H
H -- A --> J
J --> K[Self-hosted CI]
K --> L[Auto-merge on green]
L --> M[Post-merge cleanup + deploy]
M --> N[State recorded, ticket closed]
end
subgraph Conductor ["Human-in-loop (ad hoc)"]
O[Resolve A/B/C decisions]
P[Triage 'human decision needed' tickets]
Q[Update memory artifacts AGENTS.md]
end
C --> D
H --> O
N --> A
O --> J
The conductor's job is not to type code. It's to:
- Approve gates that didn't auto-continue (typically 5–15 a day).
- Resolve "human decision needed" tickets where the agent surfaced a real product trade-off.
- Update the memory artifacts (
AGENTS.md, learnings docs) when something new is discovered. - Triage incoming tickets and pick tomorrow's outcomes.
That's a 2–3 hour cognitive workload spread over a 17-hour day. The remaining 14 hours is the agents working, with you periodically saying "yes" or "hold on, let's think about this."
For the broader pattern of "one person, full stack, small infrastructure footprint", see The Solo Founder Stack I Use to Ship at Scale.
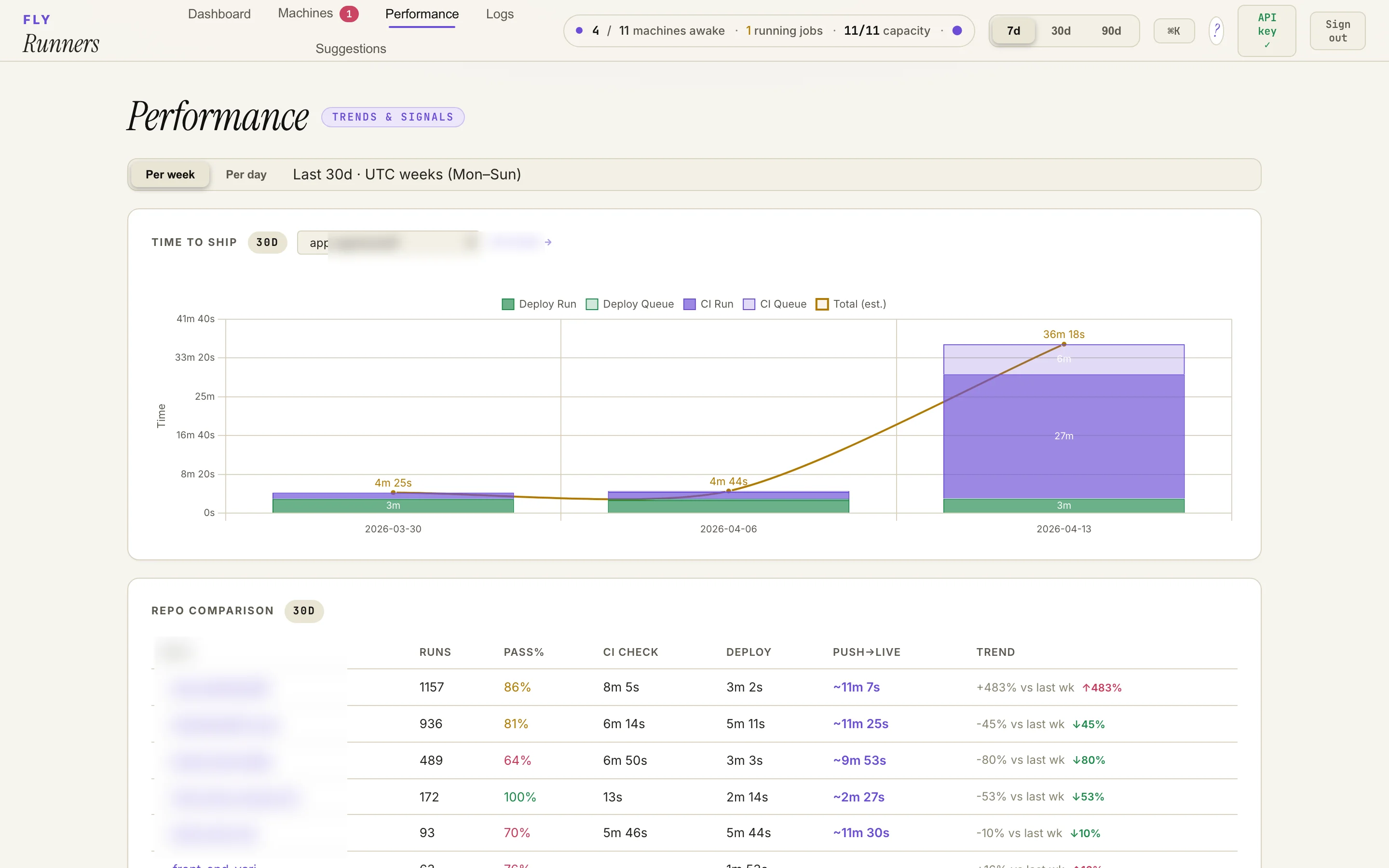 Same dashboard, performance tab. The bar on the right of the top chart is a 36-minute week — a real example of "the conductor lost the loop on Tuesday and the queue ballooned." The per-repo table below shows the wide range of pass rates and weekly trend swings you actually see across a 12-repo fleet.
Same dashboard, performance tab. The bar on the right of the top chart is a 36-minute week — a real example of "the conductor lost the loop on Tuesday and the queue ballooned." The per-repo table below shows the wide range of pass rates and weekly trend swings you actually see across a 12-repo fleet.
Five things that surprised me in the field
Auto-continue is the unlock. Without skill-decided auto-continue on green-path ships, you become a meat-jiggle clicking "yes" 99 times a day. With it, you click "yes" maybe 8–15 times, and the rest happen behind the scenes. This single feature is the difference between "agent-assisted" and "agent-driven."
The pre-ship reviewer is more valuable than the writer. Most engineering attention goes to picking the best writer model. In practice, the reviewer is where quality lives. An A-tier writer with a B reviewer produces B PRs. A B-tier writer with an A reviewer (six lenses, parallel, auto-fix the obvious) produces A PRs. Spend your model budget on review, not writing.
State files beat chat. Hook-injected state from a JSON file on disk is what lets the system survive IDE switches, browser refreshes, and overnight sleeps. Chat is volatile and gets compacted. Treat the JSON state file as the source of truth and the chat transcript as a UI layer over it.
Self-hosted CI pays for itself the first day, not the first month. The math at 99 PRs/day is so lopsided that the runner pool cost less than one day of GitHub-hosted minutes during the first week. The setup is one weekend. Don't put this off.
Fast-model routing for sub-agents is a 10× cost win at zero quality loss. Using a fast/cheap model for the six-lens reviewers (instead of the writer's model) drops review cost by ~10×. The findings are essentially identical because review is a checking task, not a creating task, and small models are extremely good at checking.
What this doesn't fix (be honest)
This isn't a clean win across the board. The honest tradeoffs:
- Test debt outpaces velocity on UI refactors and dev-only surfaces. The 25-PR audit's six lower grades (B/C/D) all share one failure mode: substantial change, no test files touched, sometimes a few
as anyescape hatches alongside. The pattern is consistent — backend / API / data PRs ship with tests; UI refactors and internal dev-tool surfaces often don't, because the agent (correctly) judges them lower stakes. The fix is to dispatch a "backfill tests for yesterday's untested PRs" agent each morning. I haven't built that yet. - No second pair of human eyes. Review is by my own agents. They're rigorous but they share my blind spots. For genuinely high-stakes work, a human collaborator is still strictly better than any number of agents.
- Production blast radius is real. 16 PRs into a single backend in 24 hours is a lot of surface area to regress. Even with strong pre-ship gates, observability and rollback discipline matter more than ever.
- Cost: ~$50–200/day in LLM tokens (Sonnet for the writer, Haiku for the six reviewers, occasional Opus for plan sanity checks) on top of the very cheap self-hosted CI. That's the cost of a single junior engineer's hourly rate, not a salary, but it's not zero.
- Cognitive load on the conductor is real even when fingers don't type. Holding 12 product graphs in your head at the level of "what's the next outcome" is a different exhaustion from coding, but it is exhaustion. Pacing matters. Sustainable looks more like 8 active hours a day, not 17. I'm working on it.
How to start agentic engineering (zero to first agent ship in a week)
If you have a week of focused effort, you can have a workable v1 of this stack running on one repo:
Day 1–2 — Write your first three skills. A ship skill, a commit skill, a review skill. Even a rough version. Force phase markers ("emit SHIP OPENING: exactly like this"). Force a sub-skill return contract ("when you return from the review, emit SHIP ENTRY REVIEW: and continue, do not stop"). Don't worry about perfect; worry about unambiguous.
Day 3 — Add a pre-ship-verify.sh that runs lint + typecheck + test + production build. Make it a hard gate in the ship skill. The skill should refuse to proceed if the script returns non-zero. Document explicitly: "running npm test directly does not satisfy this step." You're paying the same cost as a human running CI locally, in 30 seconds, before the slow-path push.
Day 4 — Install one IDE hook that injects state on prompt submit. Ten lines of bash, ten lines of JSON config in ~/.claude/settings.json or ~/.cursor/hooks.json. The hook reads the state file, formats a system reminder, prints it to stdout. Test the failure mode: kill the agent mid-ship, start a new chat, see if the next prompt picks up the state automatically.
Day 5 — Stand up self-hosted runners on a single small VM. Doesn't have to be Fly. Can be a dedicated Hetzner box, a single EC2 instance, anything. Move CI for one repo over. Bake in your common dependencies. Verify the cost math on real workloads.
Day 6 — Try a real ship. Pick a small change. Watch where the agent drifts. Tighten the skill. Note every place you had to intervene; those become tomorrow's hard rules.
Day 7 — Add a second skill. A verify skill (light/heavy modes for QA). A design skill (token-locked UI work). A handoff skill for cross-repo. Each new skill makes the next one cheaper because you're reusing the same patterns: phase markers, hard gates, sub-skill return contracts, hooks.
By the end of week two you'll have a routine. By the end of month one you'll be running multi-repo ships. By the end of month three the question won't be "can I run an agent fleet" but "what should I have the fleet do today."

If you've read Streamline Your Development Workflow with Reusable Cursor Skills or How We Migrated from Local Env Chaos to Infisical, this is the next layer up — the same patterns, applied to the whole shipping flow rather than individual editor moves. If you'd rather skip the bumping-into-walls phase and hire an AI developer who has already wired this stack at production stakes, that's also an option.
One last thing
The number that matters in this field report isn't 99 PRs. It's "1 day vs 18 months." Both of those numbers come from the same kind of person — engineers who actually wired up the agentic loop and ran it at production stakes. The gap between them is almost entirely the orchestration layer described above.
Agentic engineering doesn't replace engineers. It gives each engineer the leverage of a small team — if they invest in the orchestration layer. The bottleneck moved. It used to be how fast you could type. Now it's how well you can describe a workflow precisely enough that an agent can execute it without drifting.
If any of this sounds like the kind of thing you're trying to figure out — running an agent fleet, sizing self-hosted CI, sketching your first ship skill, or just deciding whether the orchestration tax is worth it for your team — reach out. Happy to compare notes; might save you a few weeks of bumping into walls I already bumped into.